





Introdução: Por que ter um IA pessoal importa?
Em um cenário cada vez mais conectado, a privacidade tornou-se a maior preocupação ao usar IAs na nuvem. Contudo, a tendência de modelos de linguagem locais, como o IA pessoal, vem ganhando força justamente por oferecer controle absoluto sobre seus dados. Além disso, manter uma IA 100% offline elimina riscos de vazamento e garante respostas instantâneas, sem depender de conexão ou limites de API.
Assim, este guia prático mostrará como você pode instalar um IA pessoal no seu PC, usando ferramentas robustas como Ollama e LM Studio. Você receberá instruções passo a passo, exemplos de configuração e recomendações para tirar o máximo proveito de sua IA privada. Vamos lá?
1. Preparando o Ambiente Local
Antes de instalar qualquer modelo de IA, é fundamental preparar seu ambiente. Você vai precisar de um computador com capacidade de processamento razoável — modelos menores como o LLaMA 3.2 funcionam bem com 8 GB de RAM, mas modelos mais robustos exigem 16 GB ou mais.
1.1. Requisitos mínimos recomendados
- Sistema operacional: Windows 10+, macOS (Intel ou Apple Silicon), Linux
- RAM: 8 GB (mínimo), 16 GB (recomendado)
- Espaço em disco: de 2 GB até 70 GB, dependendo do modelo
- GPU dedicada (opcional): melhora o desempenho, mas não é obrigatória
1.2. Ferramentas que usaremos
- Ollama (para baixar e rodar modelos localmente)
- Open WebUI (interface gráfica baseada em navegador)
- Docker (para rodar o WebUI de forma portátil):
- Caso queira isolar a instalação, Docker facilita o gerenciamento dos containers onde rodarão Ollama e seus modelos. No Windows, baixe o Docker Desktop e ative o WSL2. Já no macOS, instale o Docker for Mac e habilite recursos de virtualização.
- LM Studio (alternativa apenas para macOS com chip M1, M2 ou M3)
Com esses preparativos, você estará pronto para executar instâncias locais de IA. Caso opte por não usar Docker, garanta apenas a instalação de bibliotecas Python como torch e transformers em um ambiente virtual (venv), embora o método containerizado seja mais robusto.
Com esses preparativos, você estará pronto para executar instâncias locais de IA. No entanto, caso opte por não usar Docker, é essencial garantir a instalação de bibliotecas Python, como torch e transformers, em um ambiente virtual (venv). Ainda assim, vale lembrar que o método containerizado é mais robusto.
2. Instalando o Ollama para IA pessoal
O Ollama transformou o jogo ao permitir executar LLMs locais com poucos comandos. Para criar seu IA pessoal, siga este passo a passo:
2.1. Baixar e instalar o Ollama
Acesse o repositório oficial (ollama.com) e siga as instruções de download para Windows, macOS ou Linux. Após a instalação, abra o terminal e confirme com:
ollama --versionSe retornar a versão instalada, algo como “ollama version is 0.9.0”, prossiga para o próximo passo.
Para saber mais comandos, pode executar a instrução abaixo:
ollama --help
2.2. Importar um modelo de linguagem
O Ollama disponibiliza uma ampla variedade de modelos de inteligência artificial, permitindo que você escolha aquele que melhor atende às suas necessidades. Seja para processamento de linguagem natural, geração de imagens ou outras aplicações avançadas, a plataforma oferece opções diversificadas que garantem flexibilidade e eficiência no seu projeto. Para um modelo balanceado entre desempenho e tamanho, use:
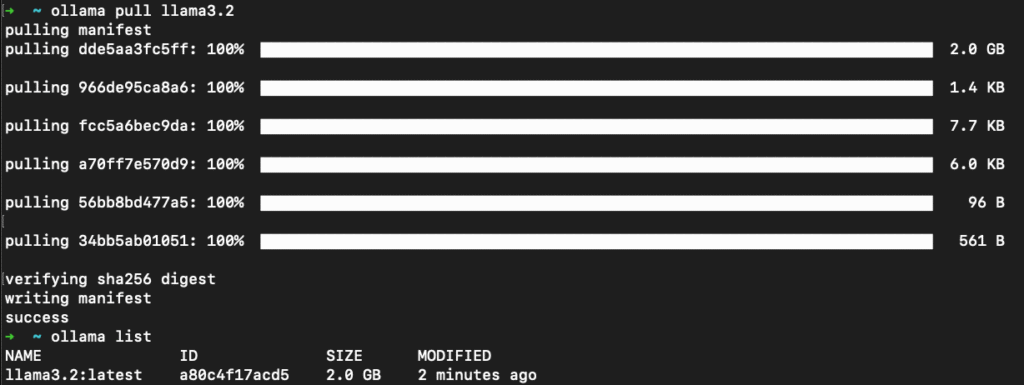
ollama pull llama3.2Esse comando faz o download do modelo para o seu PC, deixando-o pronto para uso offline. Neste tutorial, utilizamos a versão 3.2, que ocupa cerca de 2 GB. No entanto, vale destacar que alguns modelos mais avançados, como o LLaMA 4, podem ultrapassar os 67 GB de espaço.
2.3. Executar o IA pessoal offline
Com o modelo pronto, inicie um servidor local executando:
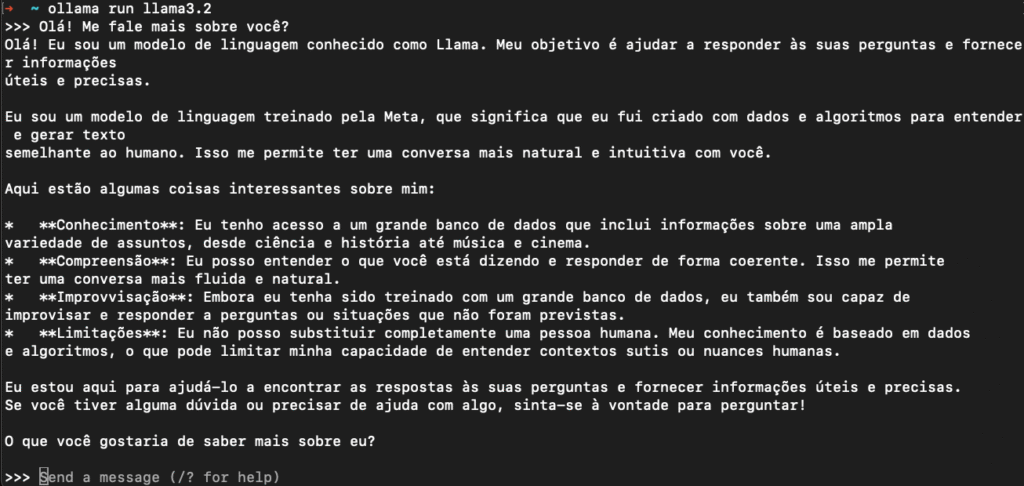
ollama run llama3.2
Assim, você conversa diretamente com seu IA pessoal offline, sem nunca sair do seu computador.
Esses comandos tornam o processo simples e rápido. Dessa forma, você pode experimentar respostas, personalizar prompts e explorar recursos avançados sem precisar depender da nuvem.
3. Interface Gráfica com Open WebUI
Apesar de o Ollama funcionar perfeitamente via terminal, muitos usuários preferem uma interface visual semelhante ao ChatGPT da OpenAI. Para isso, utilizaremos o Open WebUI.
Mas por que usar o Docker? O Docker permite que você execute o Open WebUI sem precisar configurar manualmente dependências, bibliotecas e servidores. Ele encapsula todo o ambiente necessário em um container isolado, pronto para uso com apenas um comando.
Rodando o Open WebUI:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main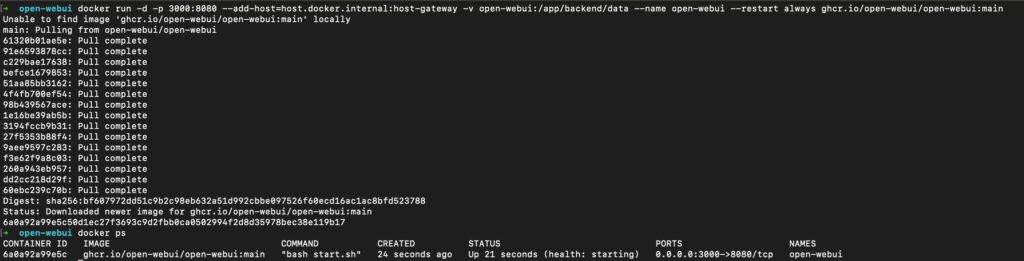
Depois disso, acesse http://localhost:3000 no navegador. Agora você tem um “ChatGPT pessoal” com interface amigável e funcional.
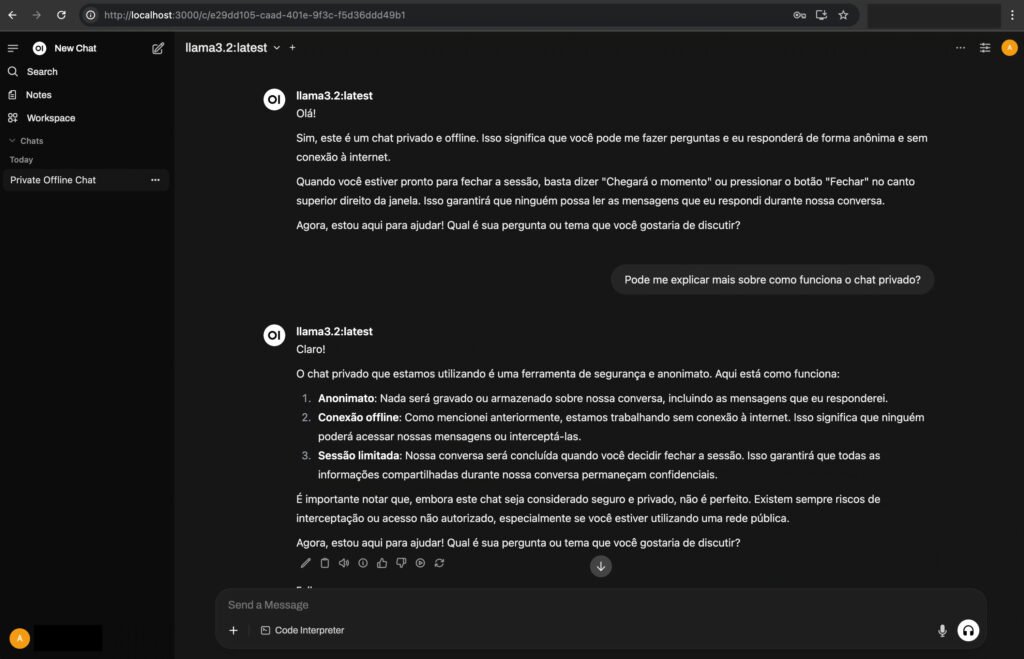
3. Alternativa: configurando o LM Studio
Caso prefira interface gráfica, o LM Studio é outra excelente opção para seu IA pessoal offline, neste caso não precisa instalar o Docker. Veja como configurá-lo:
- Download e instalação:
Visite o site oficial do LM Studio e baixe a versão compatível com seu sistema operacional. Execute o instalador e siga as instruções na tela. - Importar o modelo de IA:
Após abrir o LM Studio, clique em “Add Model” e selecione o arquivo.bindo modelo baixado (por exemplo, Llama2 ou Mistral). O aplicativo fará o upload e indexará o modelo automaticamente ou procure um model diretamente na ferramenta, baixe e depois carregue para utilizar. - Interagir pela interface:
Na aba de chat do LM Studio, você pode ajustar parâmetros como “temperature” e “max tokens” de forma visual e intuitiva. Isso facilita a personalização do comportamento da IA, permitindo explorar diferentes estilos de resposta e afinar o controle sobre a interação — tudo de forma local, offline e sem complicações técnicas.
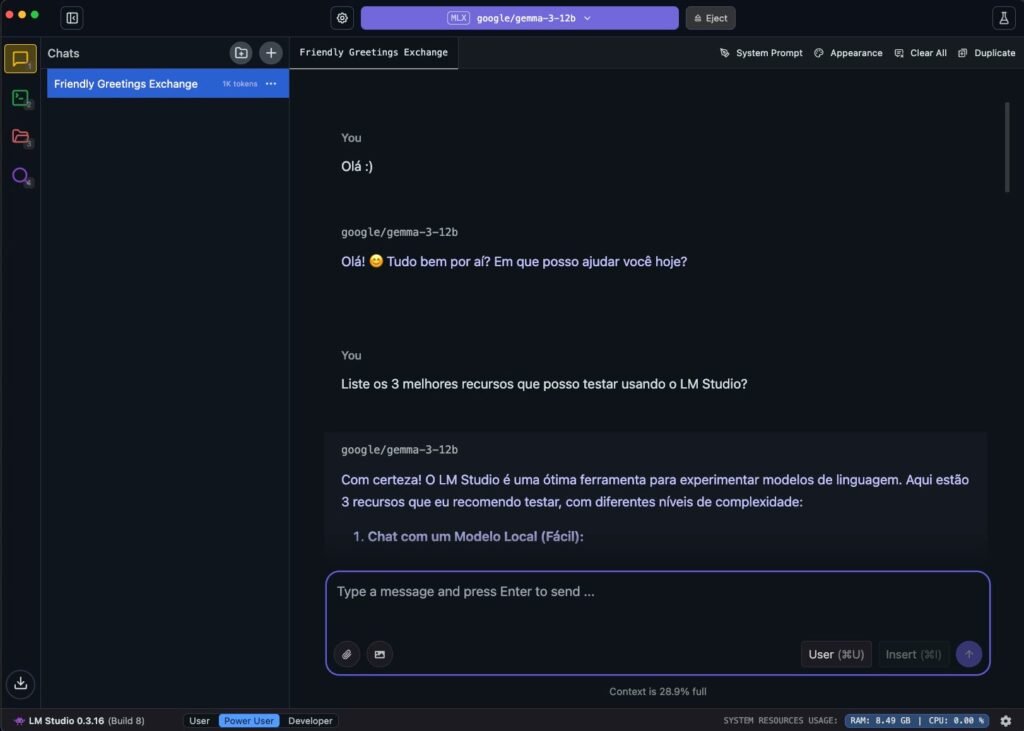
Dessa forma, tanto Ollama quanto LM Studio convertem seu computador em uma plataforma completa de IA local offline e privada, adequada para desenvolvimento e uso diário.
4. Otimizando desempenho e segurança
Para extrair todo o potencial do seu IA pessoal offline, considere as seguintes recomendações:
- Habilite a aceleração GPU:
Se seu PC tiver placa de vídeo compatível, configure Docker ou drivers locais para usar CUDA (NVIDIA) ou ROCm (AMD). Isso diminui drasticamente o tempo de inferência. - Gerencie recursos de memória:
Modelos grandes consomem muita RAM. Ajuste o parâmetro--context-sizeou use quantização de 4 bits no Ollama (ollama pull llama2:q4f16) para reduzir o uso de memória sem sacrificar muito a qualidade. - Atualize modelos e ferramentas:
Tanto Ollama quanto LM Studio recebem atualizações com melhorias de performance e suporte a novos LLMs. Verifique periodicamente por novas versões e aplique correções de segurança.
Com essas práticas, sua instância de IA pessoal offline se manterá rápida, confiável e privada. Dessa maneira, estará sempre pronta para lidar com diversas tarefas sem expor dados sensíveis.
Conclusão e próximos passos
Agora, você possui uma IA pessoal rodando 100% offline, o que garante privacidade total e autonomia tecnológica. Dessa forma, seja para redação de textos, geração de ideias ou testes de pesquisa, sua IA local estará disponível a qualquer momento. Além disso, com o avanço dos LLMs, você pode explorar modelos especializados, adaptar pipelines de dados e até criar interfaces web internas para compartilhar ferramentas com sua equipe.
Para seguir evoluindo, considere integrar plugins de voz, desenvolver agentes automatizados ou criar dashboards que monitoram estatísticas de uso. Afinal, o universo dos Local LLMs está apenas começando e, à medida que você explora mais, novas oportunidades surgirão.
E aí, gostou do artigo? Espero que tenha sido útil! Deixe seu comentário abaixo e compartilhe suas experiências ou dúvidas—vamos continuar essa conversa juntos. Além disso, se achou interessante, não deixe de compartilhar com amigos e colegas que podem se beneficiar dessas informações!





